Loading... ## 介绍 GPT-SoVITS 是花儿不哭大佬开发的低成本AI音色克隆软件,我们可以利用这个工具,克隆任何人的声音。 Github 项目地址:[https://github.com/RVC-Boss/GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS) 本地部署参考教程:[https://www.bilibili.com/video/BV1P541117yn](https://www.bilibili.com/video/BV1P541117yn) Google Colab 参考教程:[https://www.bilibili.com/video/BV1pb4y1N79s](https://www.bilibili.com/video/BV1pb4y1N79s) ## 部署 我是在自己的物理服务器上面部署的,配置是 E5 2670v2 + GT1030,操作系统是 Windows Server 2022 DataCenter。 先去 Github 下载预打包文件,解压到任意目录。注意:路径中不能有中文。 运行 go-webui.bat 文件,等几分钟,会自动打开浏览器。 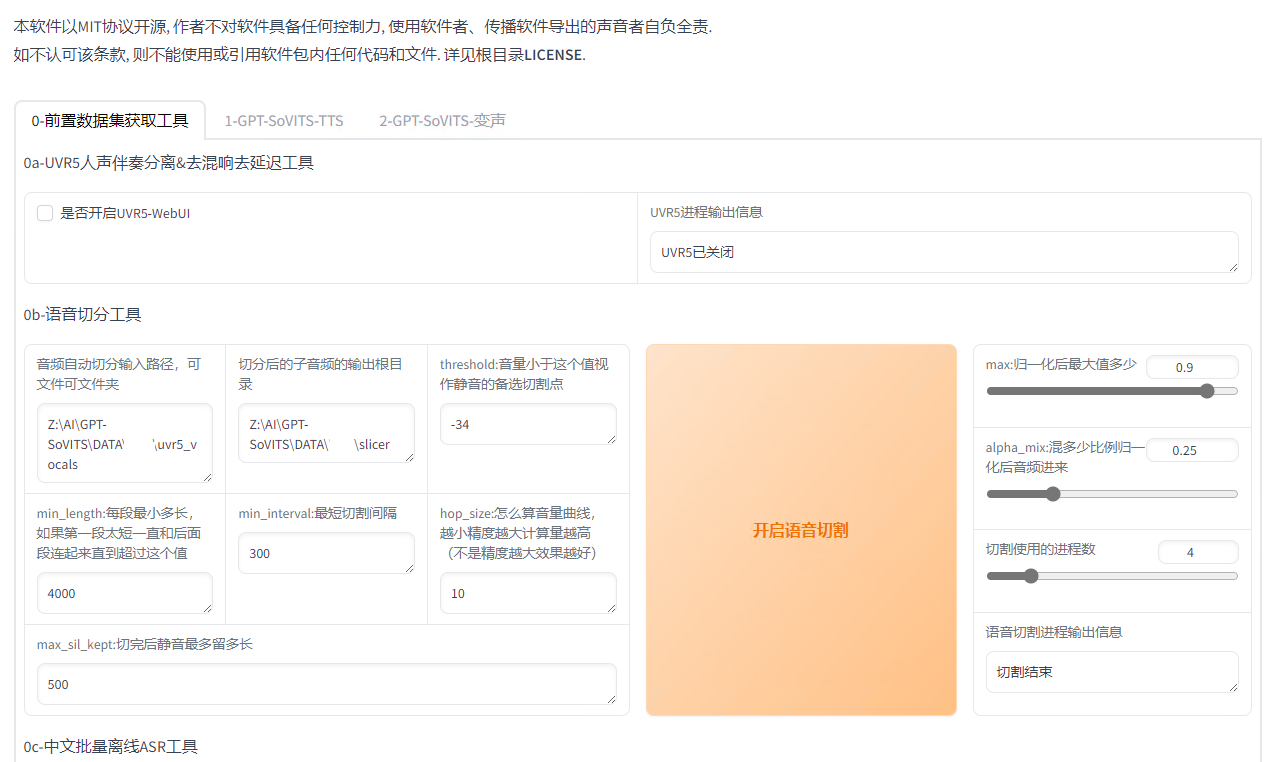 勾选“是否开启UVR5-WebUI”,然后会打开一个新的窗口。 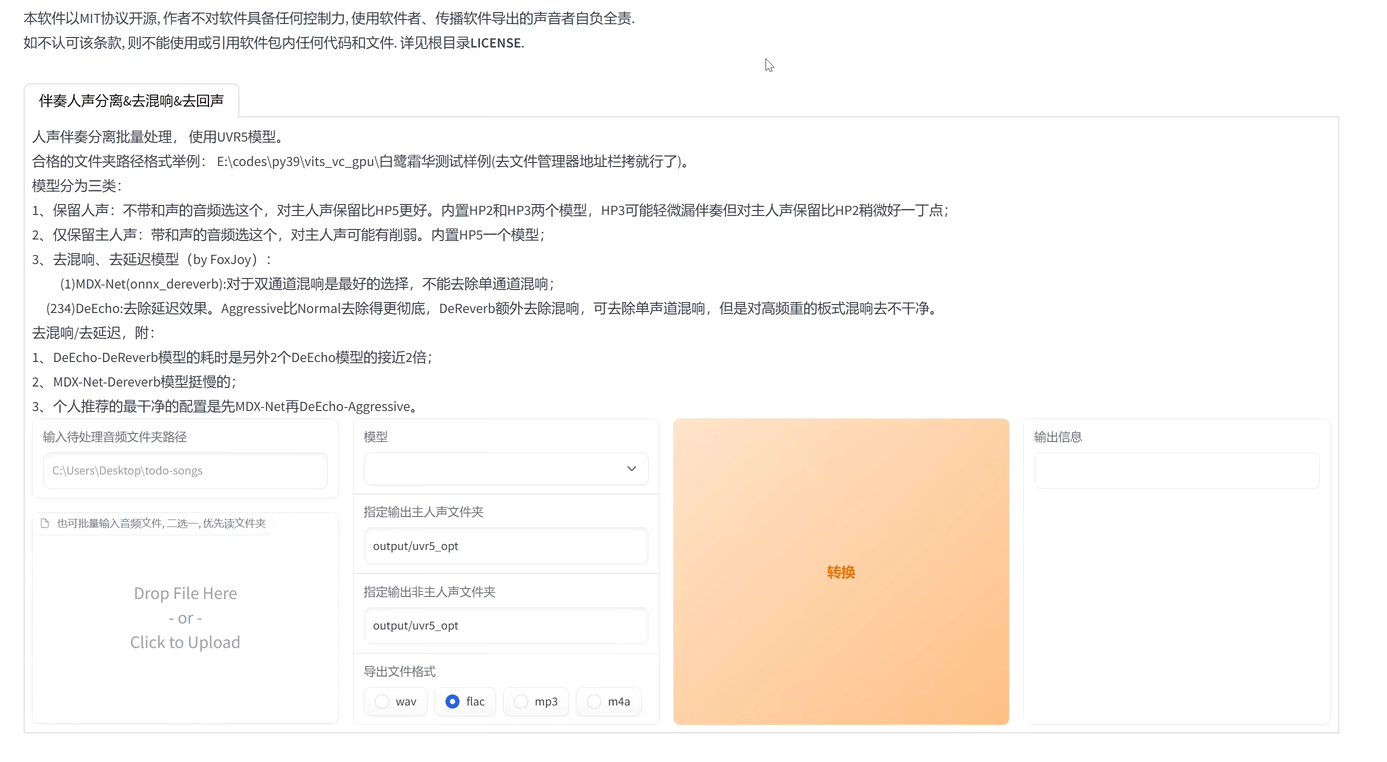 在“待处理音频文件夹路径”输入音频文件所在路径。 模型选择“H2_all_vocals”,自行指定输出文件夹,点击转换。 转换完成后,就可以关闭这个窗口了。 回到第一个窗口, 在“音频自动切分输入路径”填写处理好的人声音频所在路径。开启语音切割,显示切割结束就可以了。 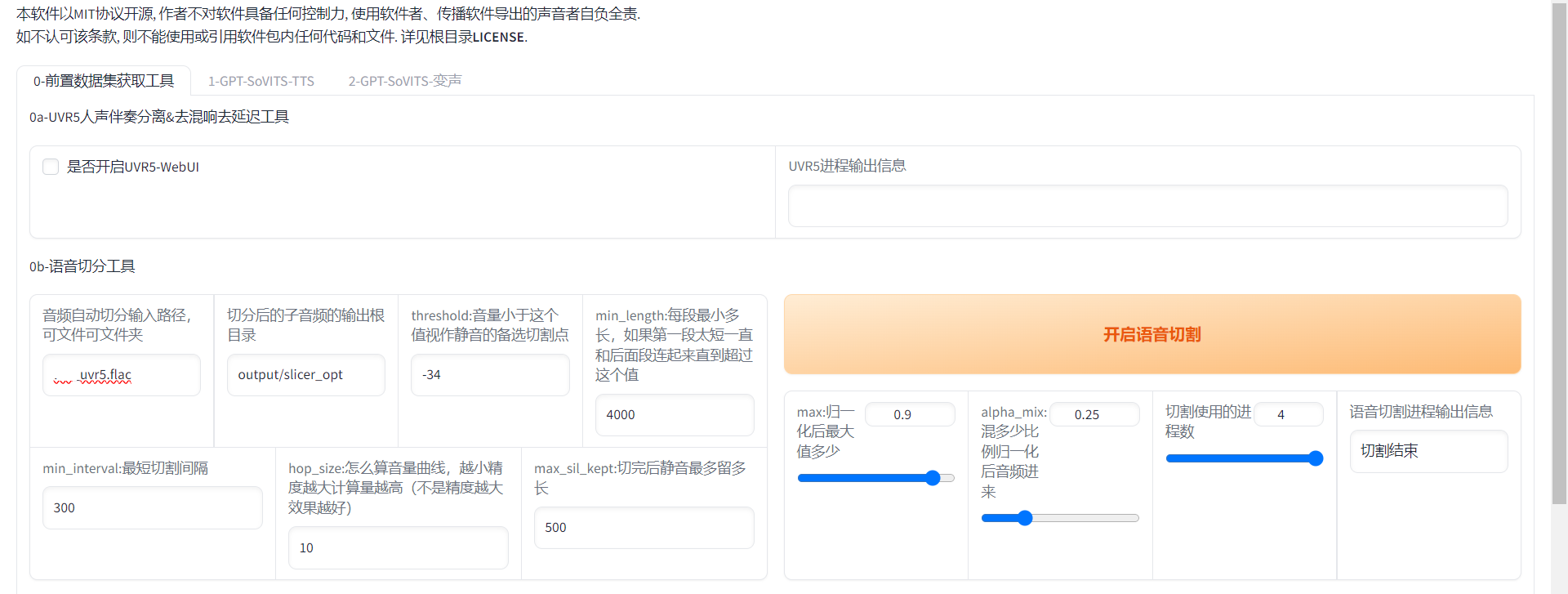 然后点击“开启离线批量ASR”,等一下会提示“ASR”任务完成。  在“打标数据标注文件路径”填写打标文件路径,打标文件默认在 \output\asr_opt 文件夹内,勾选“是否开启打标WebUI”,然后会打开一个新的窗口。  在新窗口中,可以调整音频的文本,有错误的直接改就行了。 改好之后,点击“submit text” 保存结果,再点击 “save file” 保存文件,然后就可以关闭窗口。 切换到 GPT-SoVITS-TTS 选项卡,填写实验名称,名称不能有中文。然后填写标注文件路径和切割后音频文件的路径。 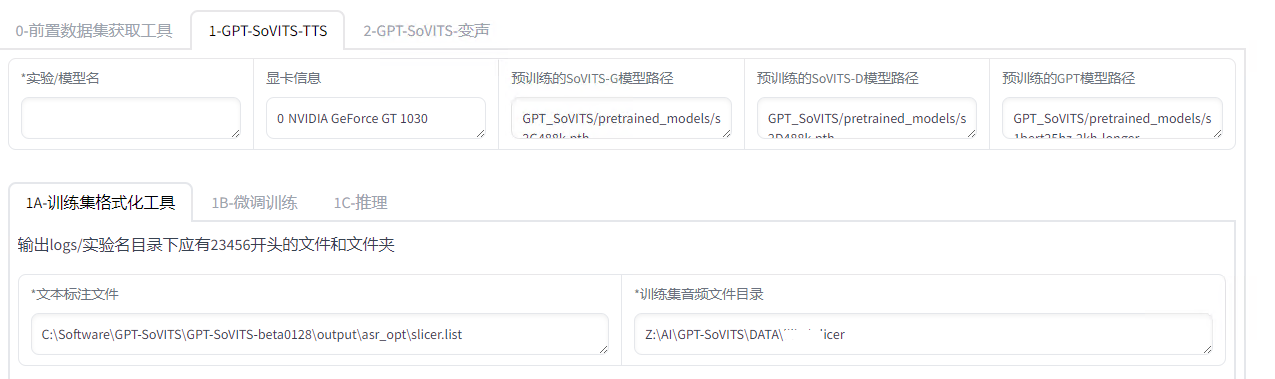 然后移动到网页最下方,开启一健三连。等一会就好了。  切换到“1B-微调训练”,开启 SoVITS 训练,完成之后,再开启 GPT 训练。  我在这一步卡住了,因为我的显卡很垃圾,爆显存了。 这时候,就需要用到 Google 的免费 GPU 服务器了。 在使用 Google Colab 之前,需要先注册一个 Google 账号,然后进入一键训练笔记本,链接地址:[https://colab.research.google.com/github/KevinWang676/Bark-Voice-Cloning/blob/main/notebooks/GPT_SoVITS.ipynb](https://colab.research.google.com/github/KevinWang676/Bark-Voice-Cloning/blob/main/notebooks/GPT_SoVITS.ipynb) 进入后点击“代码执行程序”,再点击“全部运行”,等几分钟,会输出 public URL。 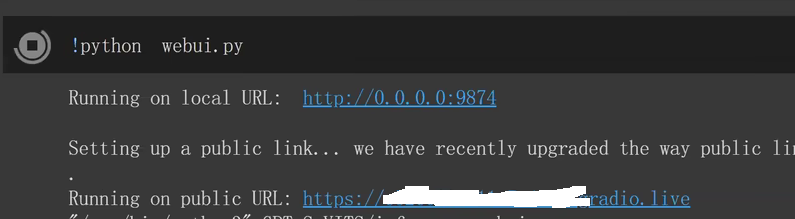 然后,打开小写的“gpt-sovits”文件夹,上传音频文件,在点击 public URL,打开 WebUI。 重复上述步骤,有了 Colab 的帮助,我们就可以很轻松的训练模型了。 完成“SoVITS训练”和“GPT训练”之后,点击“1C-推理”,刷新模型路径,选择“GPT模型”和“SoVITS”模型,两个都是选择数值最大的。 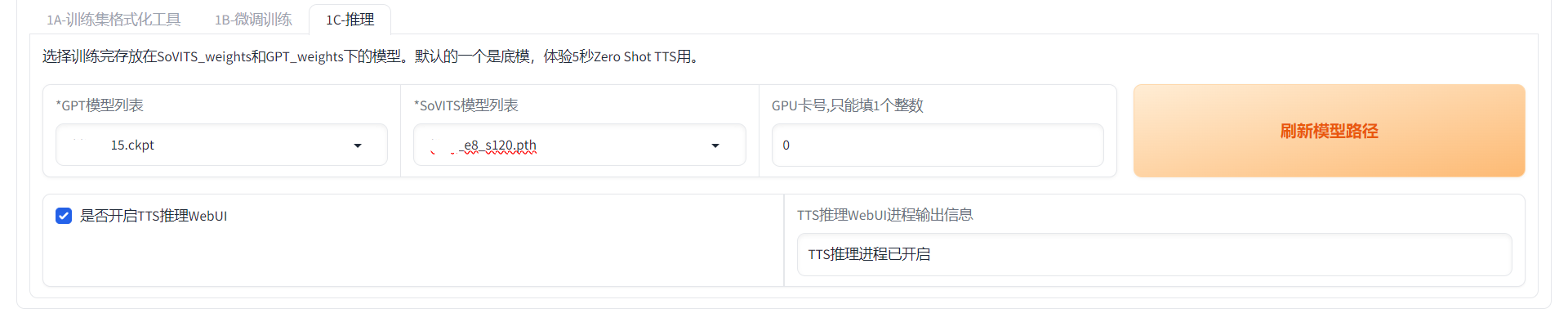 然后勾选“开启TTS推理WebUI”,等几分钟,Colab 会输出新的 public URL,点击进入TTS推理。  然后上传参考音频,输入参考音频文本,填写需要合成的文本,点击合成语音,等一下就会输出合成的语音了。 有了 Colab 训练的模型,我就可以在我自己的物理服务器上面合成音频了。 最后修改:2024 年 01 月 30 日 © 允许规范转载 赞 如果觉得我的文章对你有用,请随意赞赏
